最近接手了一个 GPU-bound 的 Web Server 开发工作,这里记录一下开发中的问题、实验数据和解决方案。
- Machine:Google Deep Learning VM
- GPU: NVIDIA A100-SXM4-40GB * 4
- Memory: 334 GB
- Driver Version: 560.35.03
- CUDA Version: 12.6
Requirements
使用 Huggingface 托管的 TrustSafeAI/RADAR-Vicuna-7B 模型做文本分类操作,输入长度不固定,需要拆分成不大于 300 字符的字符串列表分别推理,然后一起返回给客户端。
No Batch
原型开发时不考虑效率,用了非常 naive 的实现。后续使用 locust 做性能测试,得到这些结果:
1 worker with nginx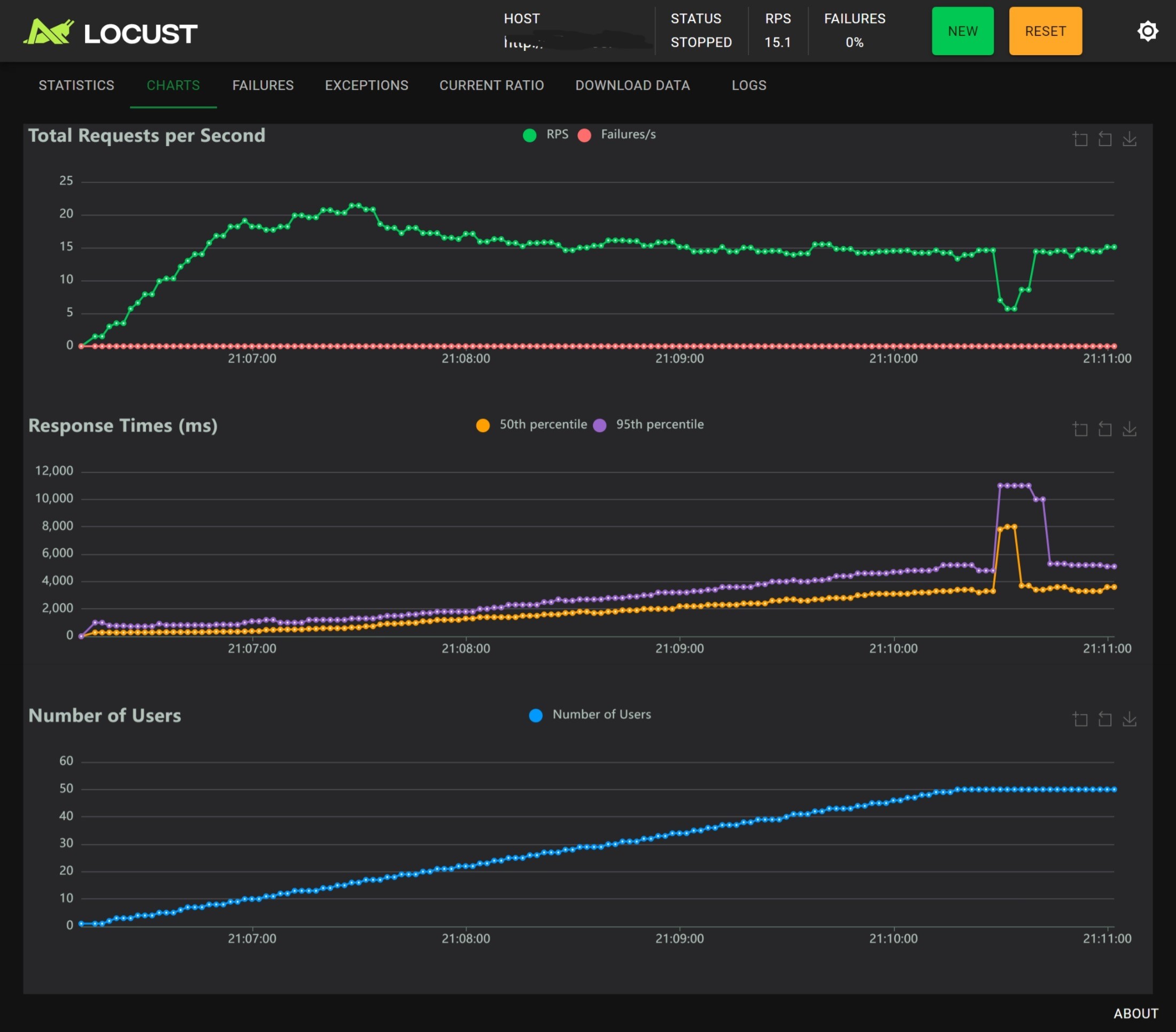
1 worker without nginx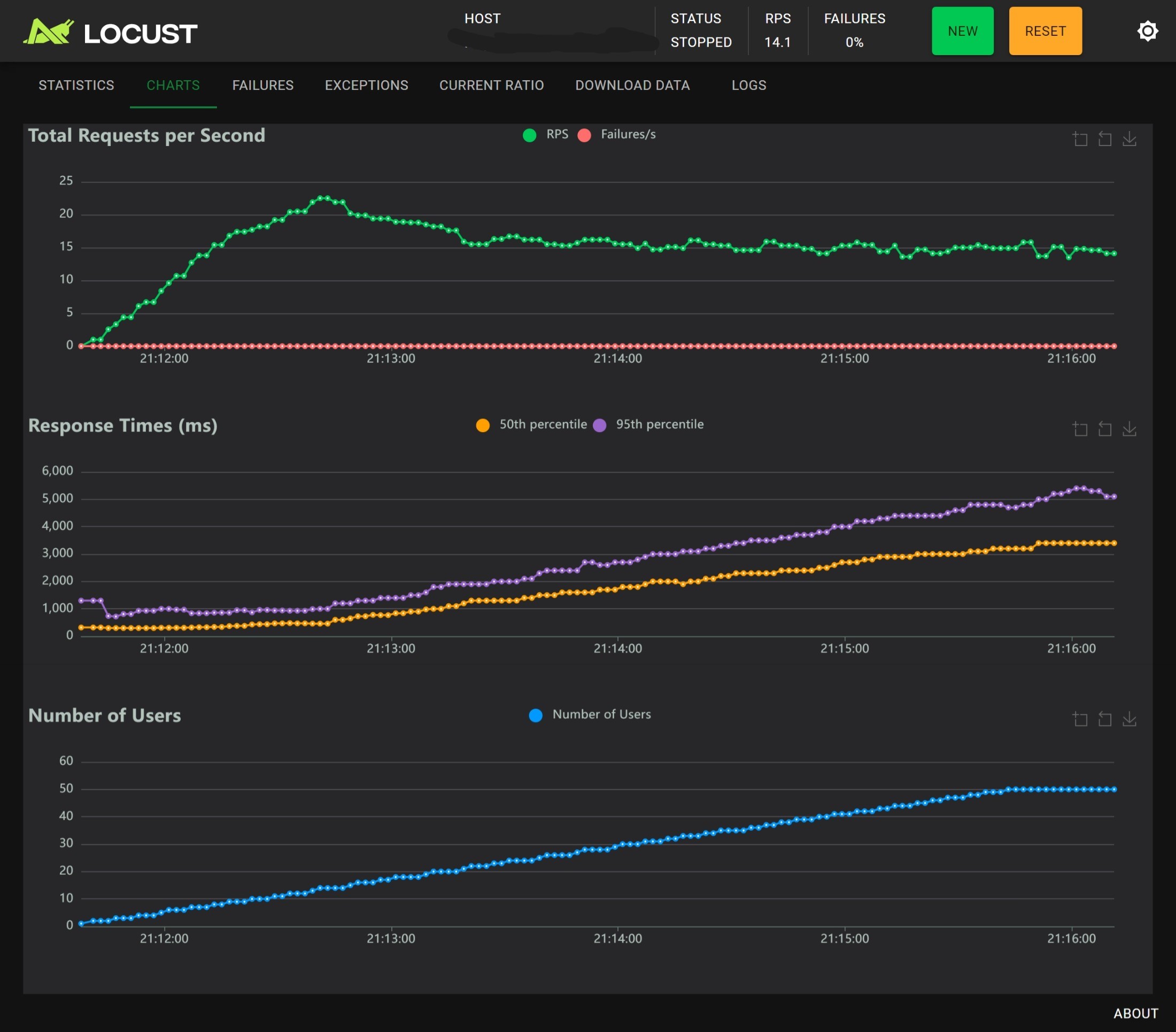
4 workers with nginx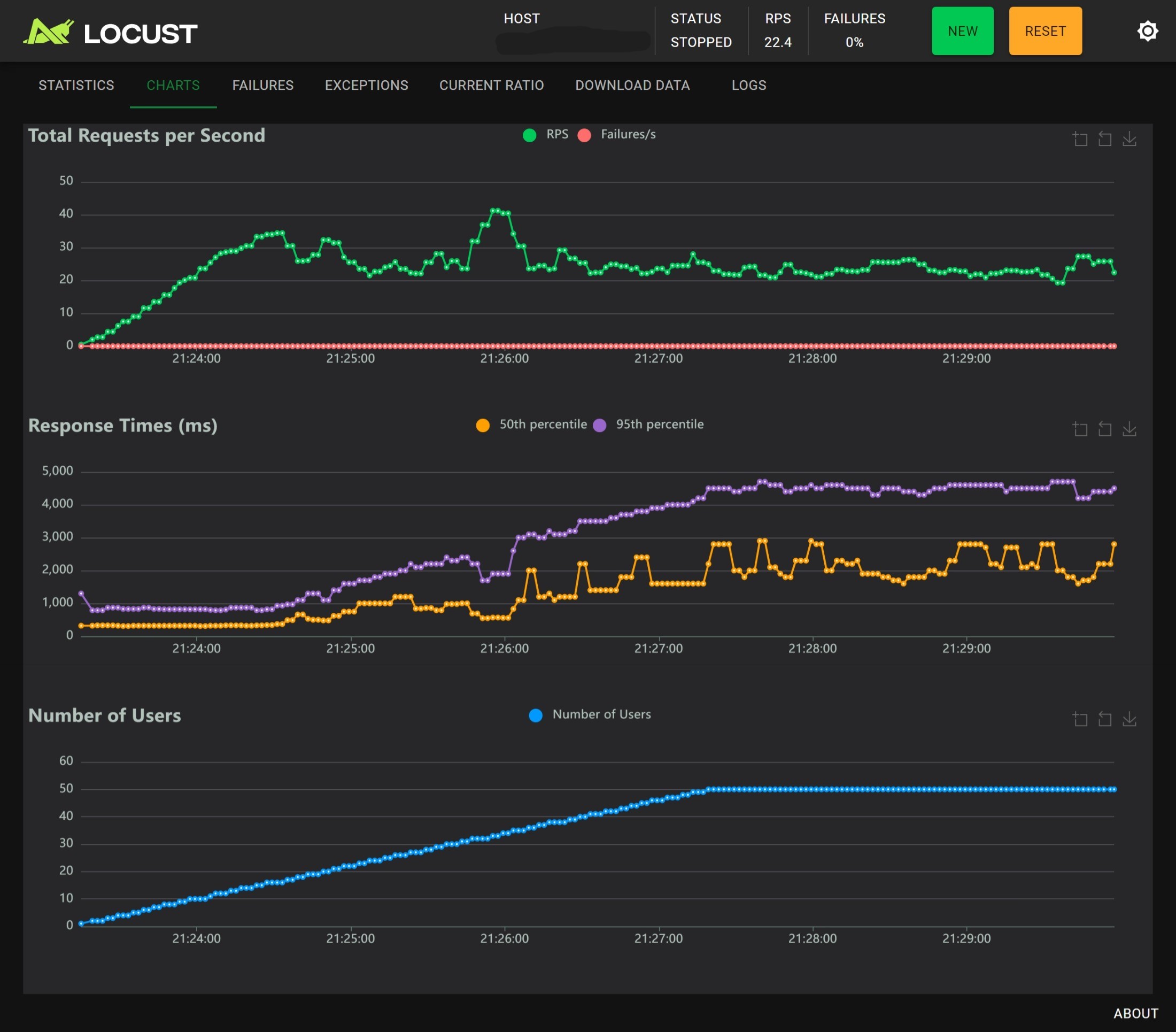
4 workers without nginx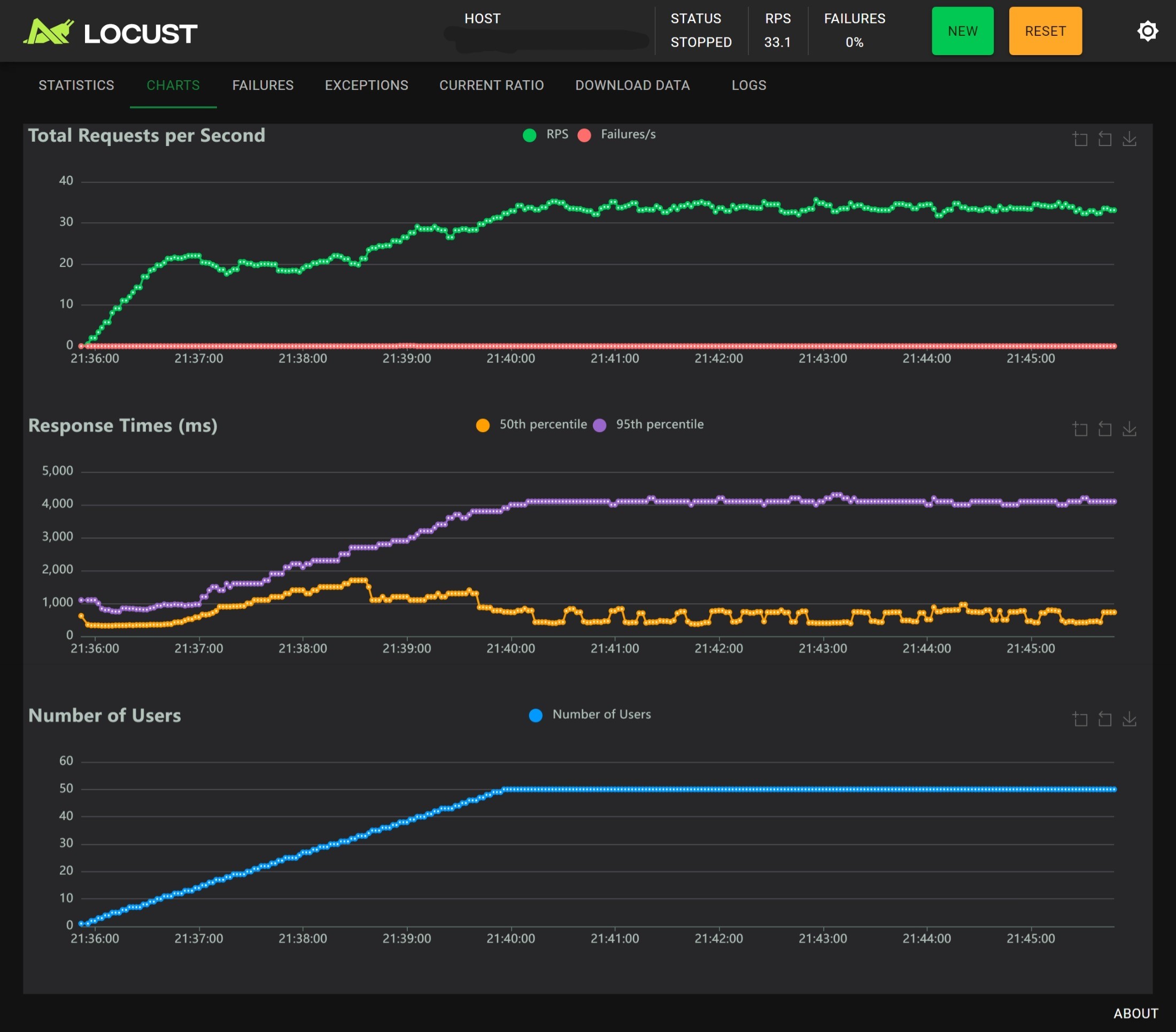
每一个 Worker 都独占一个进程,并拥有独立的显存。
从性能测试的结果可以看出:
- 单进程时用户数在 20 左右可以发挥最好的性能,RPS 不会超过 25,RTp95 大约为 1000ms,随着用户数增多 RT 越来越大,同时 RPS 越来越小,Nginx 基本没有作用;
- 多进程时用户数在 20 左右可以发挥最好性能,相较于没有 Nginx 的版本,有 Nginx 时性能和稳定性反倒是下降了,主要体现在用户数大于 40 的压力测试阶段:
- 无 Nginx 时 RPS 稳定在 34 左右,有 Nginx 时 RPS 稳定在 25 左右
- 无 Nginx 时 RTp50 < 1000ms,RTp95 ~ 4000ms,有 Nginx 时 RTp50 < 3000ms,RTp95 ~ 4500ms
结论:Nginx 基本没有作用,有时甚至会起到反作用;多进程的主要作用是提高 RPS,对 RT 的改善不明显。
Offline Batch
在测试过程应用的日志中看到这样一条提示:“You seem to be using the pipelines sequentially on GPU. In order to maximize efficiency please use a dataset”。搜索可知这条提示会在 pipe() 被调用 10 次后固定输出(ref)。从 issue 中可以得到一条启示,即最好使用批处理(batch)来加速计算过程。
写一个脚本测试一下使用批处理时的性能,大概思路是不断生成随机长度的字符串,用不同的 batch_size 并行推理,然后将开销平摊到每个字符串上,具体实现见仓库中的 script.py 文件。
测试得到的结果如下:
当字符串长度在 [100, 800] 均匀分布时:
1 | split=1, 16.771073 / 1024 = 0.016378 s/item |
当字符串长度在 [100, 300] 均匀分布时:
1 | split=1, 15.606943 / 1024 = 0.015241 s/item |
可知 batch_size 选择 16 或 32 时性能最高,这个可作为后续参数的参考值。
Online Batch
参考了 Transformers 官方文档上关于 Web Server 的建议(ref),使用异步和批处理又写了一版。
这里把关键部分放上来,一些无关紧要的地方已经删去或使用 ... 代替。
1 | async def server_loop(mq: asyncio.Queue): |
这里涉及到三个函数:
startup:钩子函数,在应用初始化后、开始接受请求前执行,用来创建server_loop异步任务。server_loop:不断从mq中接收消息,批处理式推理,然后返回给调用者。analyze_and_classify:处理 HTTP 请求时会多次调用这个函数,推理接口的封装。
按照时间顺序来描述接下来会发生的事:
startup:创建一个“全局变量”:mq = asyncio.Queue();server_loop:调用pipeline函数,加载 pipeline;server_loop:进入死循环,在时间BATCH_TIMEOUT内尝试从mq获取BATCH_SIZE_MAX个对象;analyze_and_classify:被调用(调用者是ai_detection_on_single_string),创建一个rq = asyncio.Queue(),然后把text和其他消息放入app.mq中,然后异步等待从rq获取对象;server_loop:超时或已经获取到了BATCH_SIZE_MAX个对象,如果对象列表非空,则对这些对象批处理推理,batch_size为对象的数量;server_loop:推理完成,把结果放入对应的rq,进入下一轮循环;analyze_and_classify:从rq中获取到对象并返回。
在全局范围内,mq被创建一次,rq在每次调用analyze_and_classify时都会创建一次。创建asyncio.Queue()的时间开销很小,用timeit在我的机器上测得 2.5us。
使用不同的 BATCH_SIZE_MAX 和 BATCH_TIMEOUT 进行性能测试:
BATCH_SIZE_MAX=8, BATCH_TIMEOUT=0.5: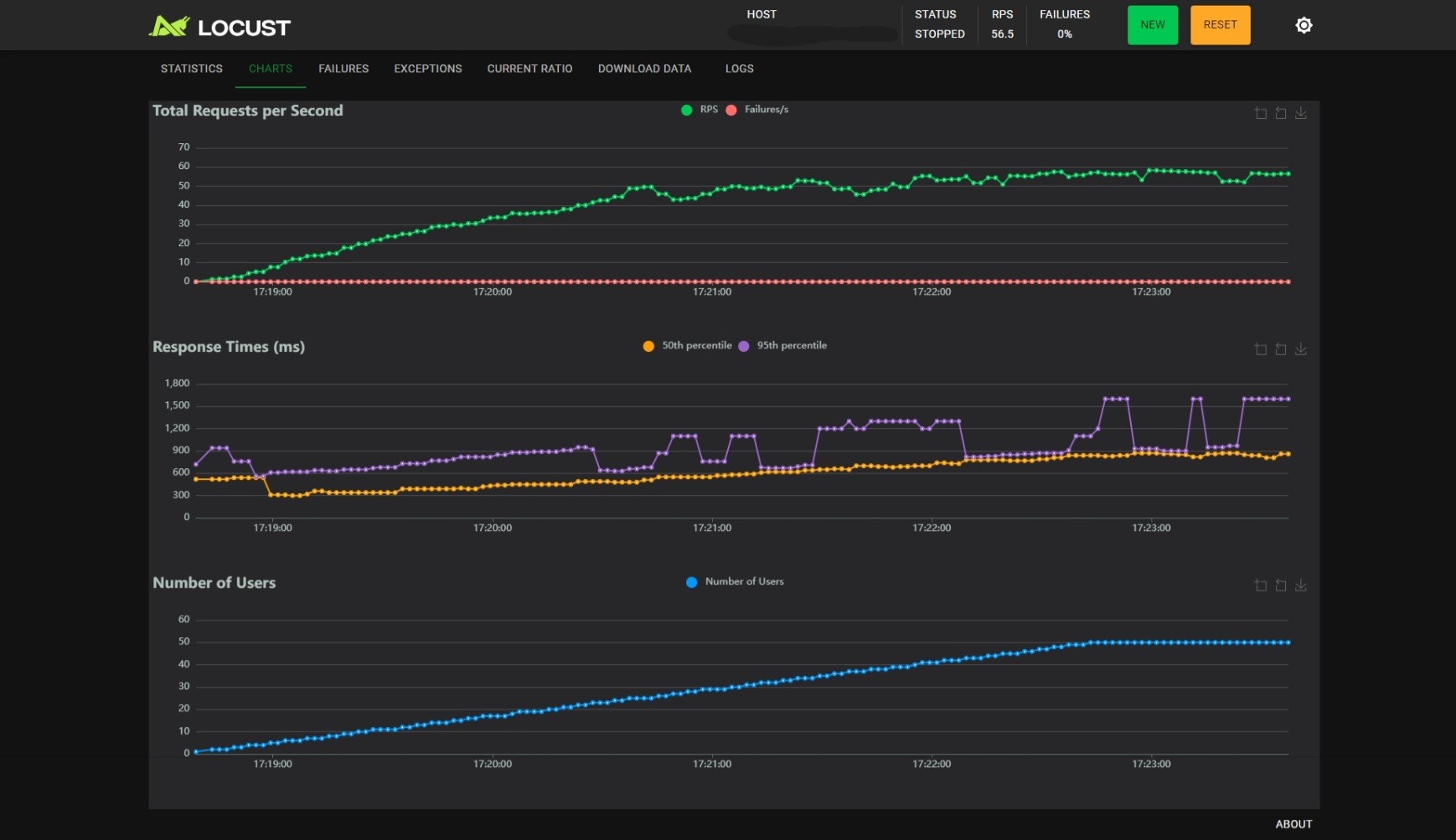
BATCH_SIZE_MAX=8, BATCH_TIMEOUT=0.3: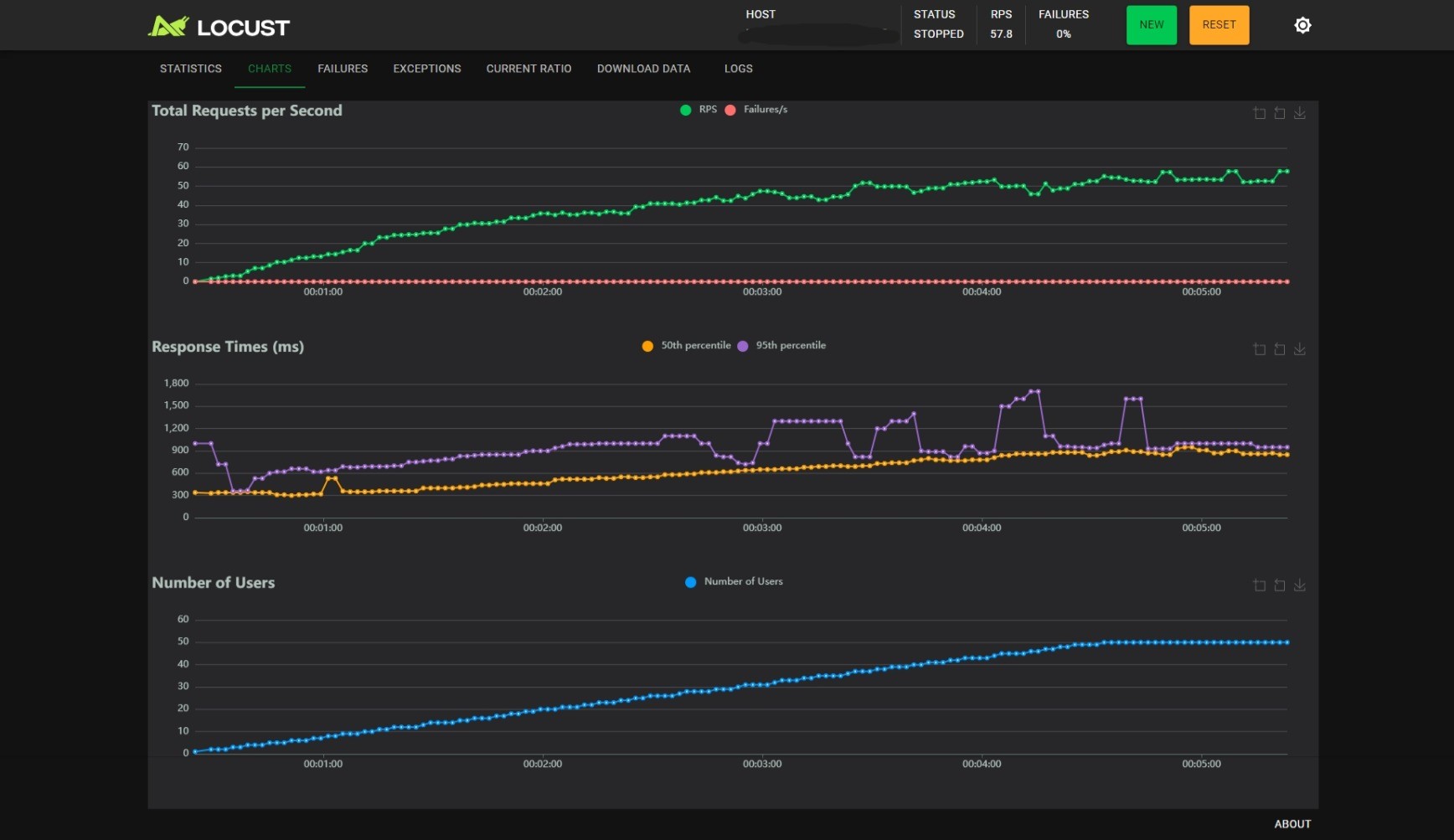
BATCH_SIZE_MAX=8, BATCH_TIMEOUT=0.1: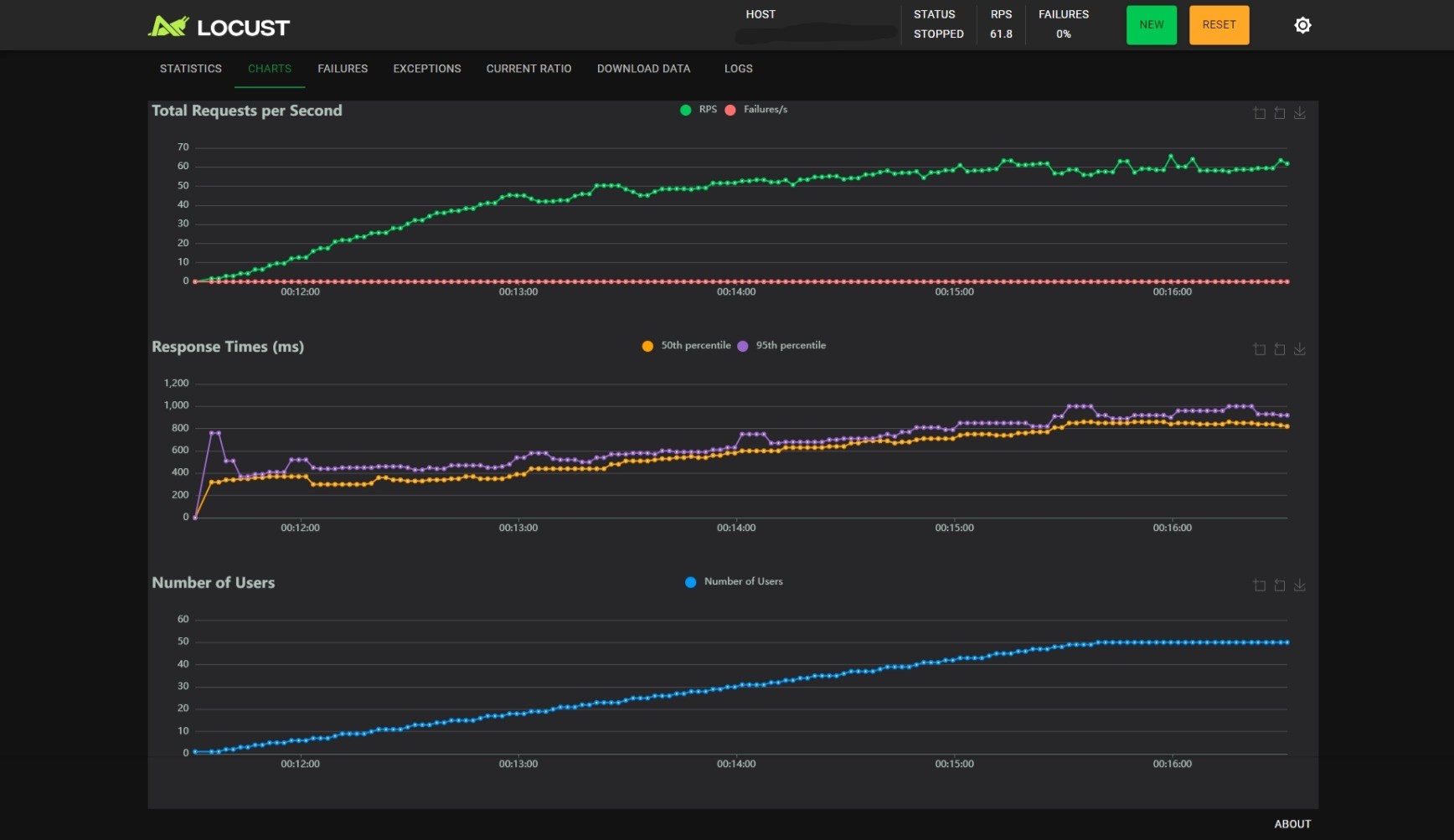
BATCH_SIZE_MAX=16, BATCH_TIMEOUT=0.5: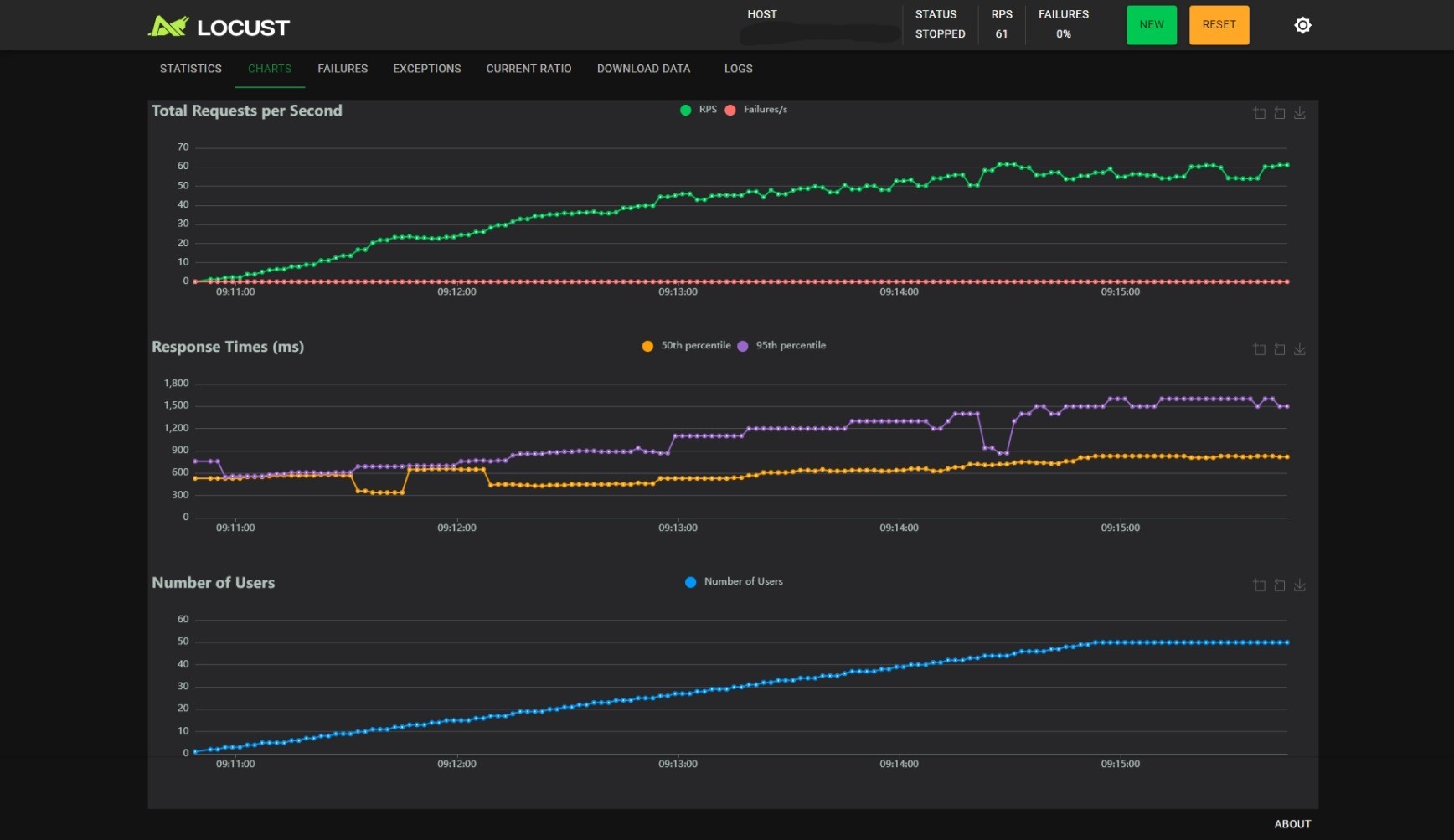
BATCH_SIZE_MAX=16, BATCH_TIMEOUT=0.3: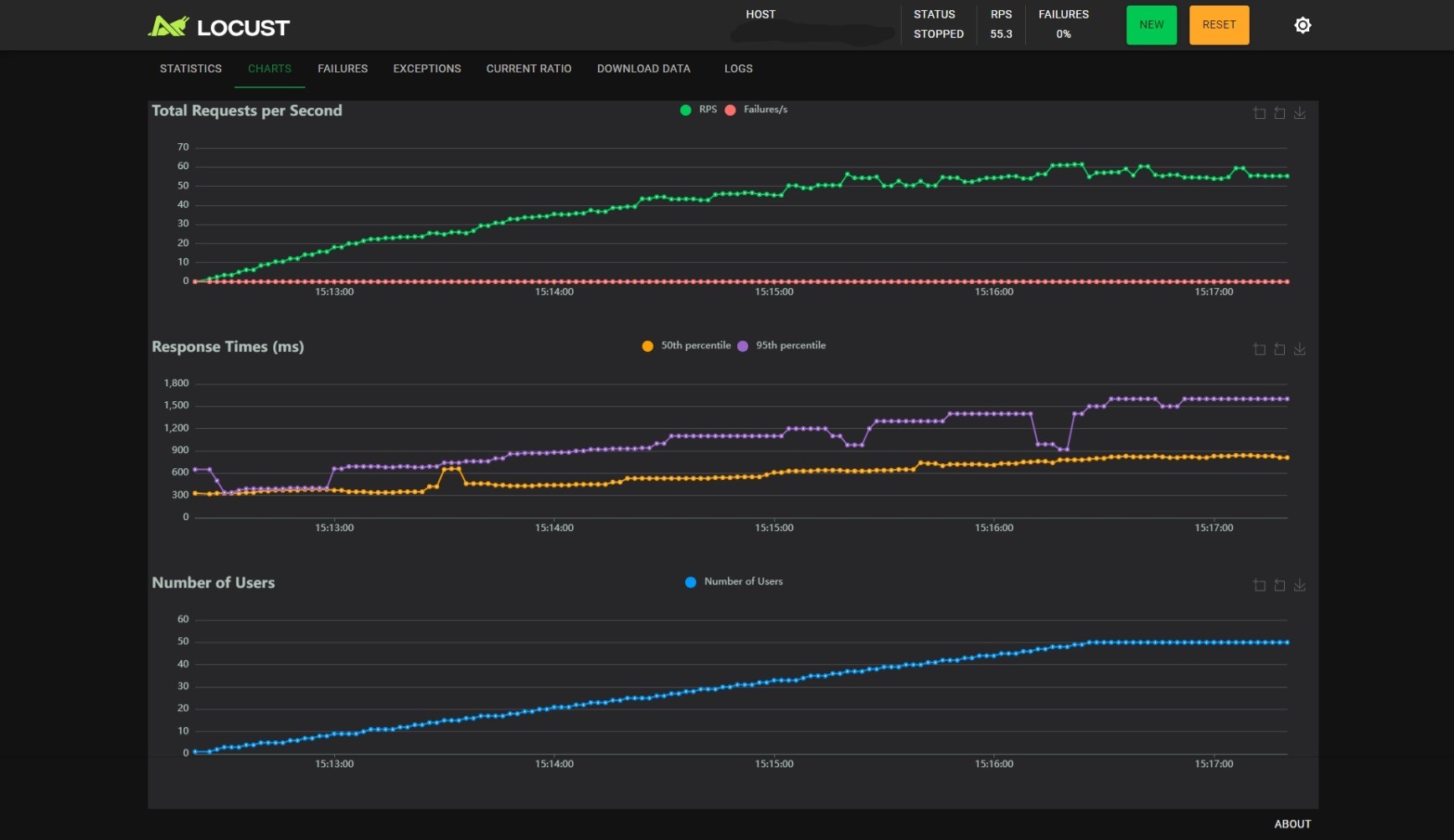
BATCH_SIZE_MAX=16, BATCH_TIMEOUT=0.1: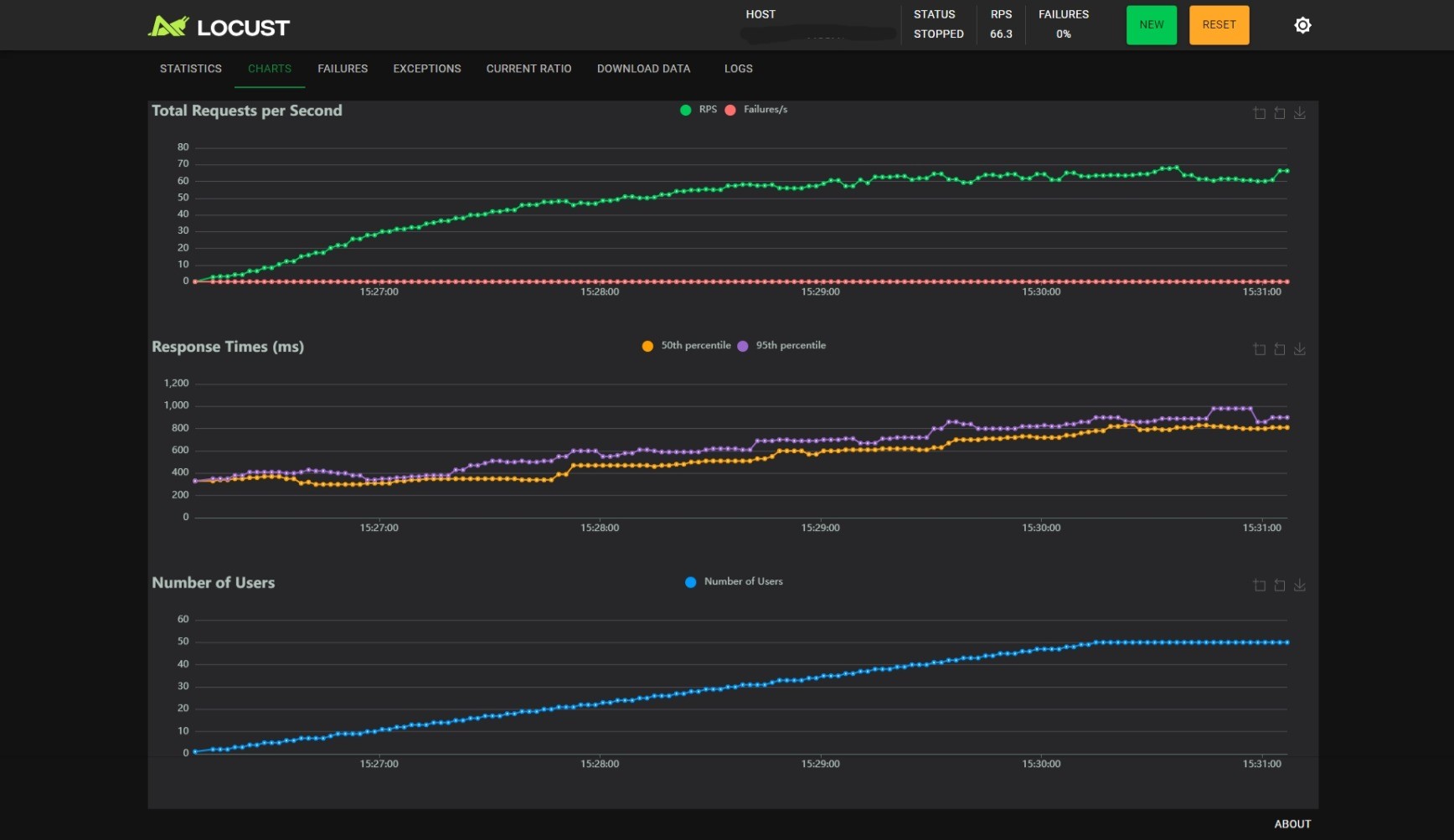
BATCH_SIZE_MAX=32, BATCH_TIMEOUT=0.5: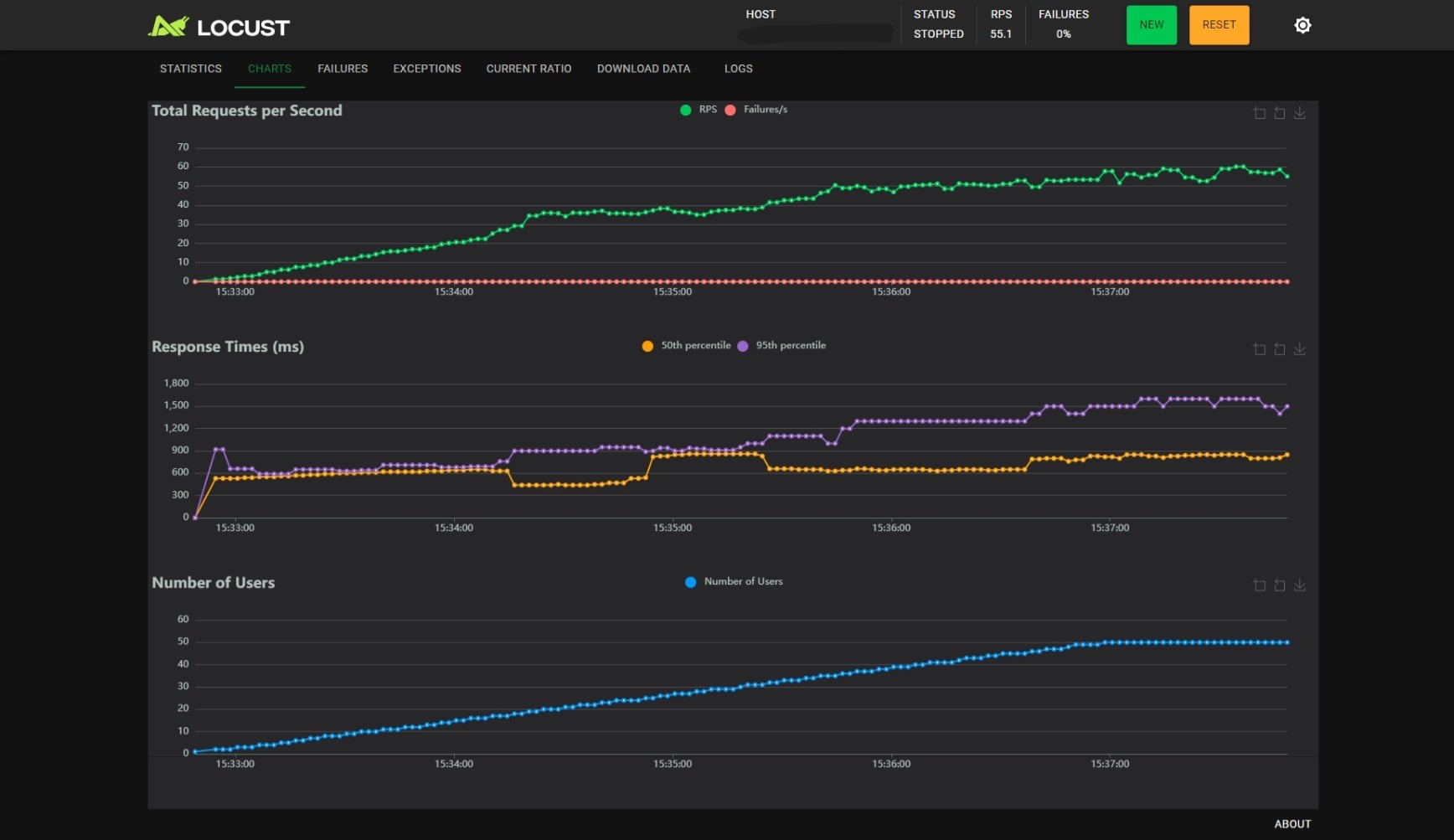
BATCH_SIZE_MAX=32, BATCH_TIMEOUT=0.3: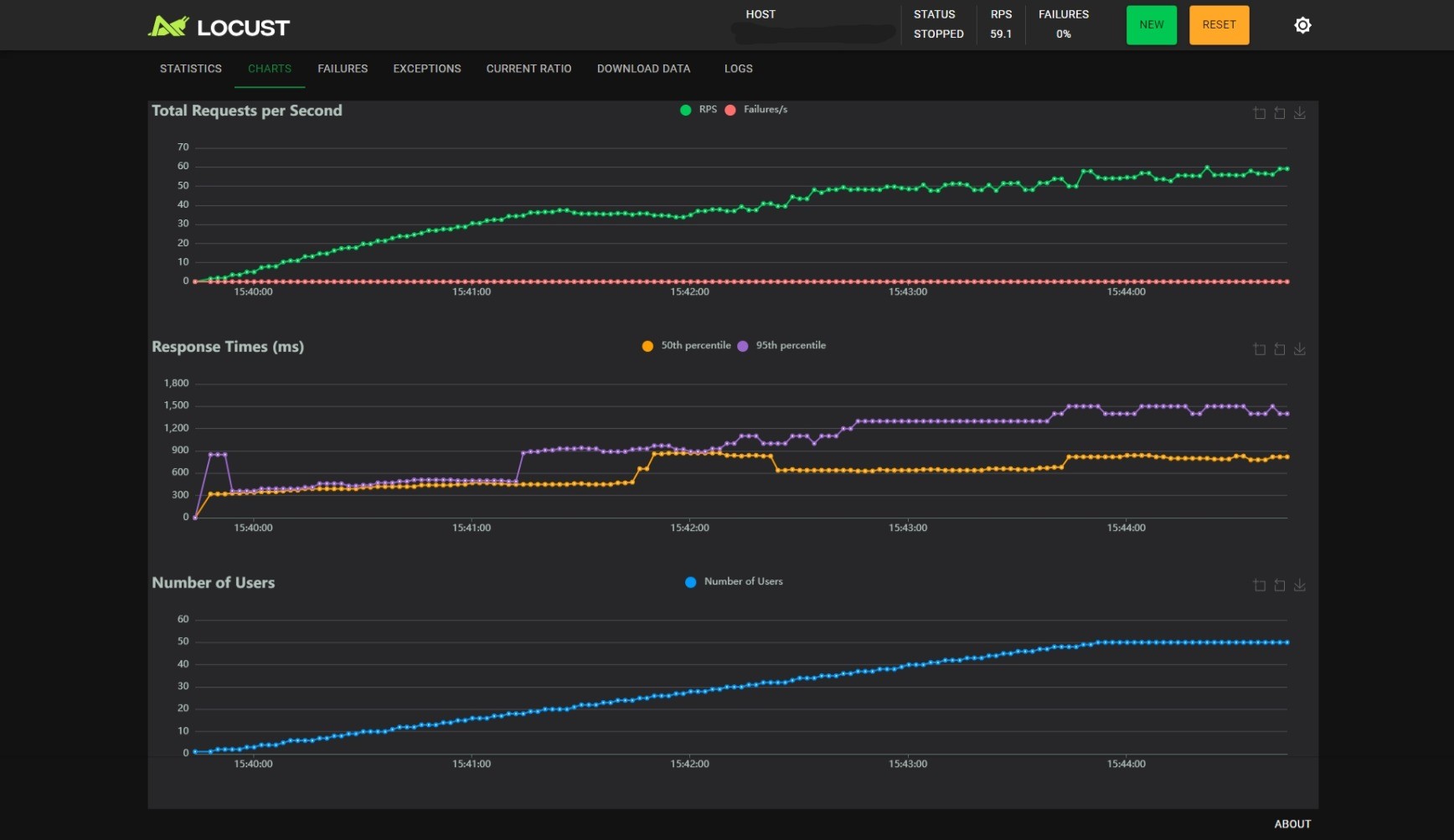
BATCH_SIZE_MAX=32, BATCH_TIMEOUT=0.1: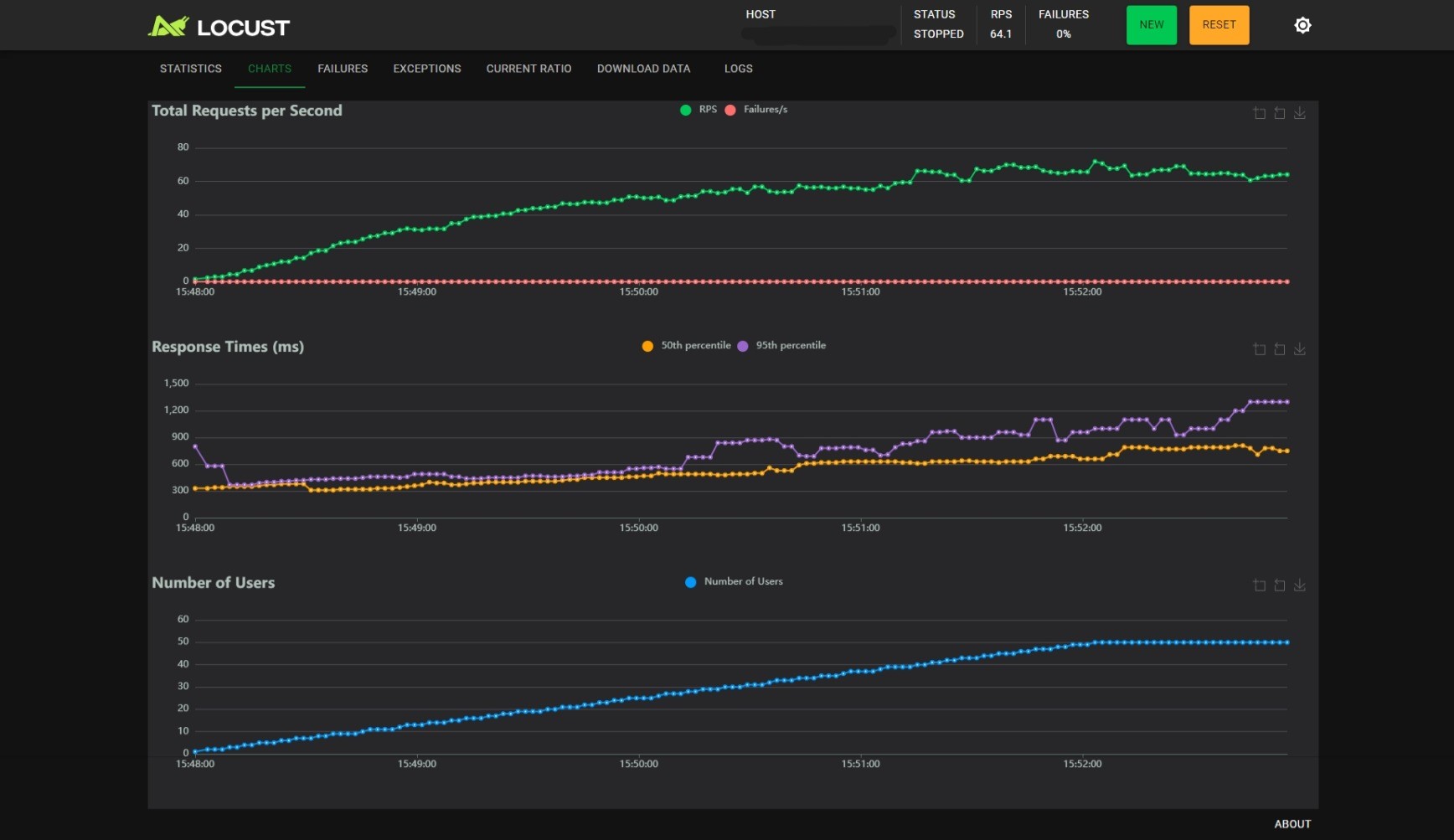
观察可以得到以下几个结论:
- 随着用户数的线性增长,RPS 增加会逐渐变慢;
BATCH_SIZE_MAX不变时,减小BATCH_TIMEOUT能小幅度提升 RPS,小幅度降低 RT,但是能提升 RT 的稳定性,当BATCH_TIMEOUT为 100ms 时尤甚;BATCH_TIMEOUT不变时,增加BATCH_SIZE_MAX能提升 RPS,但是会影响 RT 的稳定性。
尽管我们得到了这几个结论,但这也只是局限在这个实验范围内,不同的语言、实现细节、硬件规格都可能产生不同的结论。正如 Transformers 官方文档所言:
Creating an inference engine is a complex topic, and the “best” solution will most likely depend on your problem space.
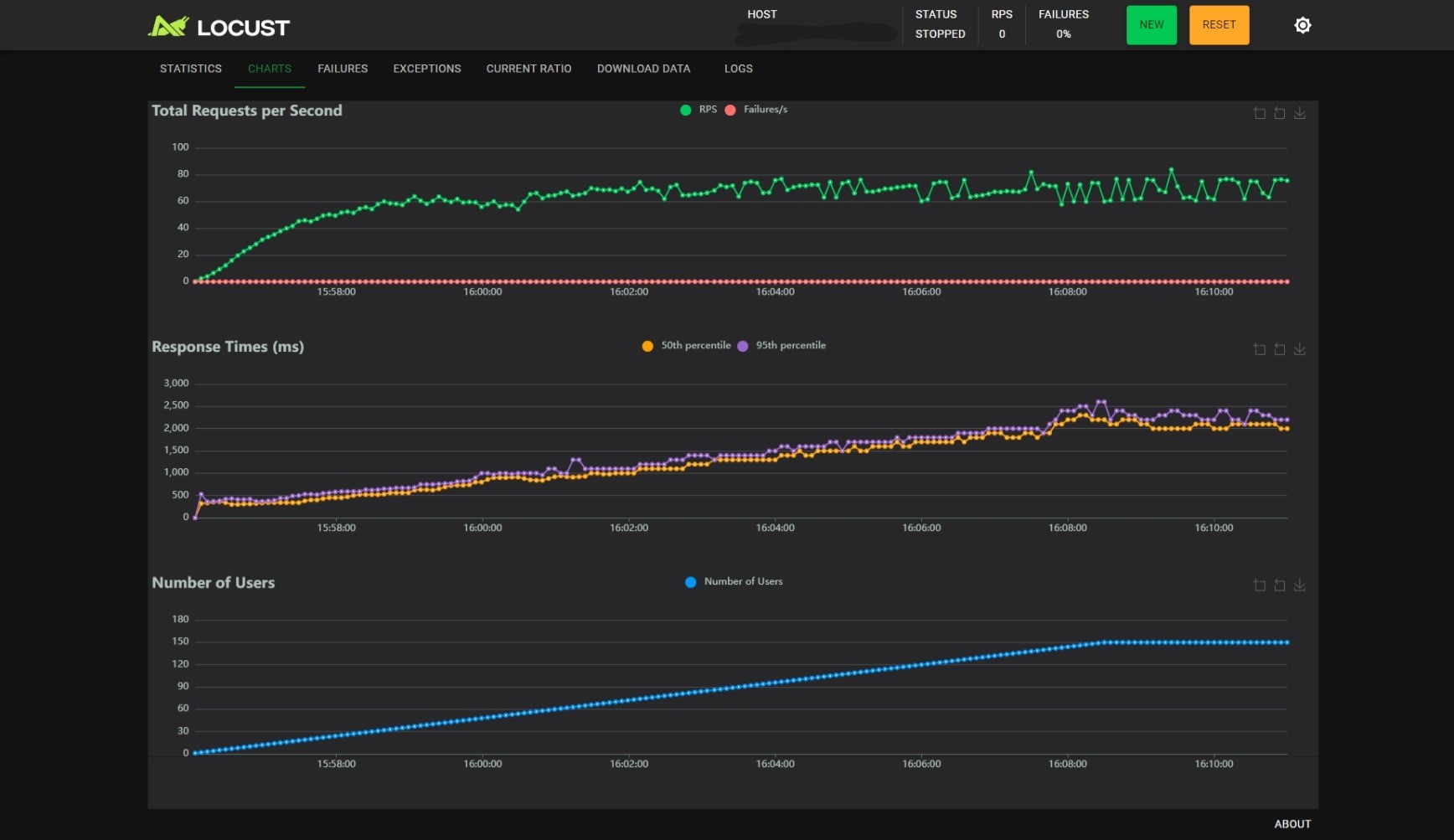
最后放上 BATCH_SIZE_MAX=16 BATCH_TIMEOUT=0.1 参数的压测结果作为结尾:
Author: HairlessVillager
Permalink: http://hairlessvillager.github.io/2024/10/11/research-on-gpu-bound-web-server/
The article is licensed under the CC BY-NC-SA 4.0 protocol by default.
Please comply with the protocol when using it.